

RAG(検索拡張生成)とは?初心者でもわかる仕組みと活用方法を徹底解説
業界トップの正確率で作業効率爆上げ!
RAG(検索拡張生成)とは、生成AIの回答精度を向上させる技術です。
従来のChatGPTなどの生成AIは、学習データに含まれない最新情報や社内の専門知識を扱えず、事実と異なる回答(ハルシネーション)を生成する課題がありました。
RAGは、外部のデータベースから関連情報を検索し、それを基に回答を生成する仕組みにより、これらの問題を解決します。
本記事では、RAGの仕組みからビジネスでの活用方法、導入時の注意点まで、初心者の方にもわかりやすく解説します。
参考記事:RAG(検索拡張生成)とは?意味・定義 | IT用語集
https://www.ntt.com/bizon/glossary/e-r/rag.html
RAG(検索拡張生成)とは?生成AIの回答精度を高める仕組み
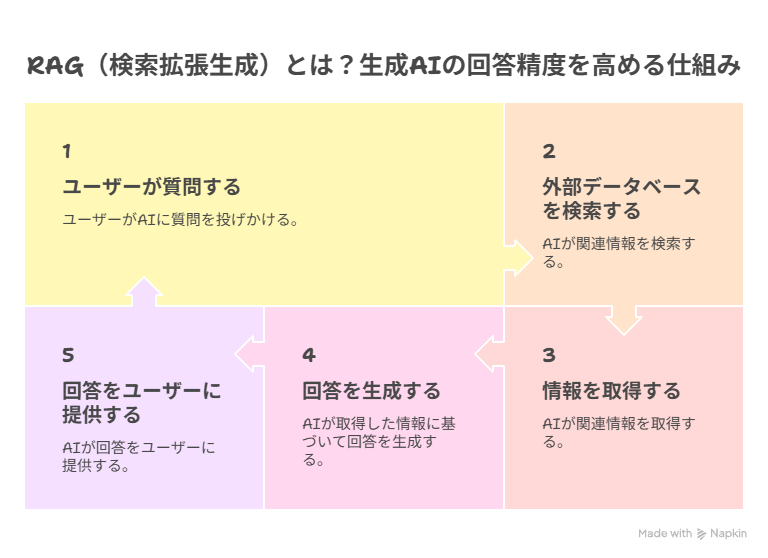
RAG(検索拡張生成)は、生成AIが外部のデータベースから情報を検索し、その情報を基に正確な回答を生成する技術です。
従来の生成AIが抱えていた「最新情報の不足」や「事実と異なる回答(ハルシネーション)」といった課題を解決する、画期的なアプローチとして注目を集めています。
RAGの定義と読み方
RAGは「Retrieval-Augmented Generation(リトリーバル・オーグメンテッド・ジェネレーション)」の略称で、日本語では「検索拡張生成」と訳されます。
RAGの仕組みは、大きく3つのステップで構成されています。
まず「Retrieval(検索)」で、質問に関連する情報をデータベースから抽出し、次に「Augmentation(拡張)」で、検索した情報をプロンプトに組み込みます。
最後に「Generation(生成)」で、拡張されたプロンプトを基にAIが回答を生成可能です。
この一連の流れにより、AIは学習データに含まれていない最新情報や専門知識にも基づいた、より正確な回答を提供できるようになります。
なぜ今RAGが注目されているのか?LLMの限界を補完する役割
従来の大規模言語モデル(LLM)は学習時に取り込んだデータしか参照できないため、学習後に発生した最新情報や、企業の社内ドキュメントなどの非公開データには対応できませんでした。
また、学習データに含まれていない情報について推測で回答するため、事実と異なる内容(ハルシネーション)を生成するリスクもありました。
しかし、RAGを活用すると外部データベースからリアルタイムで情報を検索して、その情報を基に回答を生成できるため、最新情報や専門知識に基づいた正確な回答が可能になります。
さらにデータの再学習(ファインチューニング)が不要なため、コストを抑えながら柔軟に情報を更新できる点も高く評価されており、AIが活用されている昨今、多くの注目を集めています。
従来の生成AI(GPT等)との決定的な違い
従来の生成AI(GPTなど)とRAGの決定的な違いは、「情報の参照方法」にあります。
従来の生成AIは、事前に学習したデータのみを参照して回答を生成しているため、学習後に発生した最新情報や、学習データに含まれていない専門知識には対応できません。
一方、RAGは質問を受けるたびに外部のデータベースから関連情報を検索し、その情報を基に回答を生成します。
この違いにより、RAGは最新情報や社内の専門知識に基づいた回答が可能になります。
また、従来の生成AIは回答の出典(ソース)を明示できませんが、RAGは検索した情報の出典を提示できるため、回答の信頼性が向上します。
図解でわかるRAGの仕組み|検索と生成が連携する3ステップ
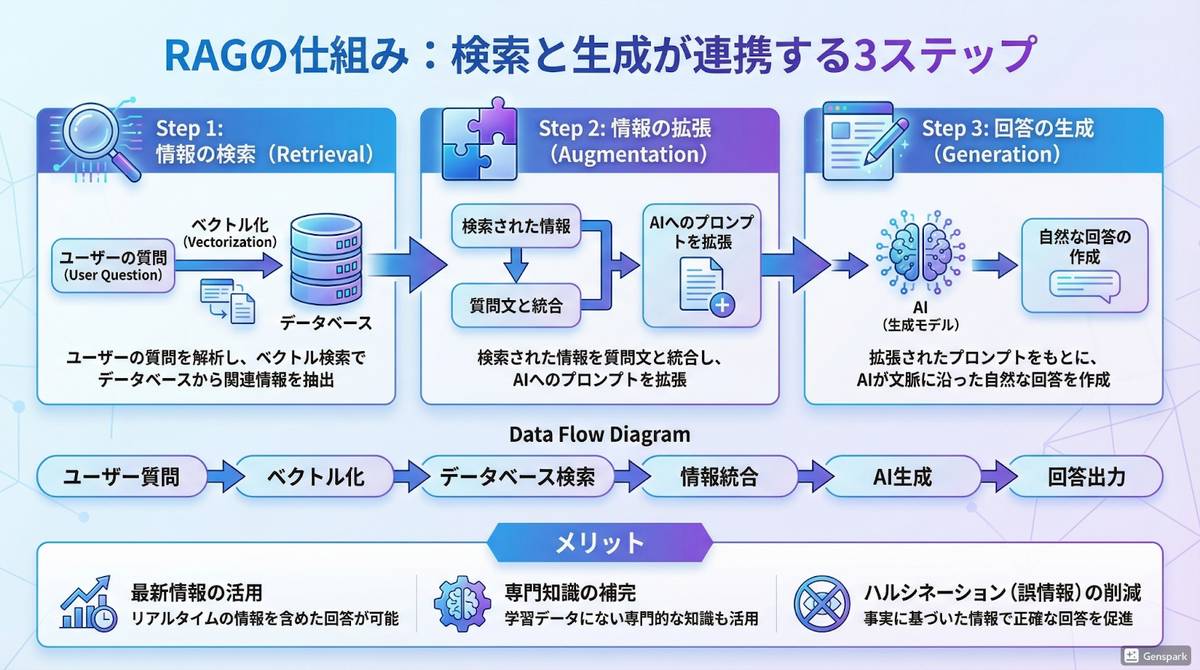
RAGの仕組みは、大きく分けて3つのステップで構成されています。
ユーザーの質問を受け取ると、まず関連する情報をデータベースから検索し、次にその情報をプロンプトに組み込み、最後にAIが回答を生成します。
この一連の流れにより、AIは最新の情報や専門知識に基づいた正確な回答を提供できるようになります。
【Step 1】情報の検索(Retrieval):関連データの抽出
ユーザーからの質問を受け取ると、システムはまず質問の内容を解析し、関連する情報をデータベースやドキュメントから検索します。
例えば「東京の気候」という質問に対して、気候の情報だけでなく、気温データや季節情報を含む情報を検索します。
検索結果は関連度の高い順にランク付けされ、最も有用な情報が選別されます。
この検索精度がRAG全体の品質を左右する重要なステップです。
【Step 2】情報の拡張(Augmentation):プロンプトへの統合
検索で得られた情報を、AIが理解しやすい形に整理し、元の質問と組み合わせます。
具体的には、抽出されたテキストや数値データを「参考情報」として質問文に付加し、AIへの指示(プロンプト)を拡張します。
例えば「東京の気候は?」という質問に対して、「以下の情報を参考に回答してください:東京の年間平均気温は15.4℃、梅雨は6月頃…」といった形で情報を補強します。
この拡張により、AIは自身の学習データだけでなく、最新かつ正確な外部情報を活用できるようになります。
【Step 3】回答の生成(Generation):文脈に沿った文章作成
拡張されたプロンプトをもとに、生成AIが自然で読みやすい回答文を作成します。
AIは提供された参考情報と質問の意図を理解し、事実に基づいた正確な回答を文章として組み立てます。
例えば、検索された気候データをもとに「東京は温暖な気候で、年間平均気温は約15℃です。四季がはっきりしており、6月には梅雨を迎えます」といった自然な文章が生成されます。
このステップでは、情報の正確性を保ちながら、ユーザーにとってわかりやすい表現で回答が提供されます。
精度の鍵は「ハイブリッド検索」の活用
RAGの検索精度を高める鍵は、「キーワード検索」と「ベクトル検索」の組み合わせとなる「ハイブリッド検索」にあります。
キーワード検索は、正確な情報が検索できるものの、文字列が完全に一致する情報しか見つけられません。
ベクトル検索は文章の意味を数値化して意味的に近い情報を見つける方法で、例えば「会議の議事録」と「ミーティングの記録」は、言葉は違いますが意味は同じなので両方検索対象となります。
ハイブリッド検索は、この2つを組み合わせた最新のアプローチです。
キーワード検索で正確な用語を拾い、ベクトル検索で意味的に近い情報を補完することで、検索の精度と網羅性が大幅に向上します。
この組み合わせにより、RAGはより適切な情報を検索し、結果としてAIの回答品質も向上するのです。
テキストで指示するだけ。抽象的なアイデアも、会議のイメージも、AIが瞬時に視覚化します
RAGを導入するメリットと、「ハルシネーション」抑制とコスト削減
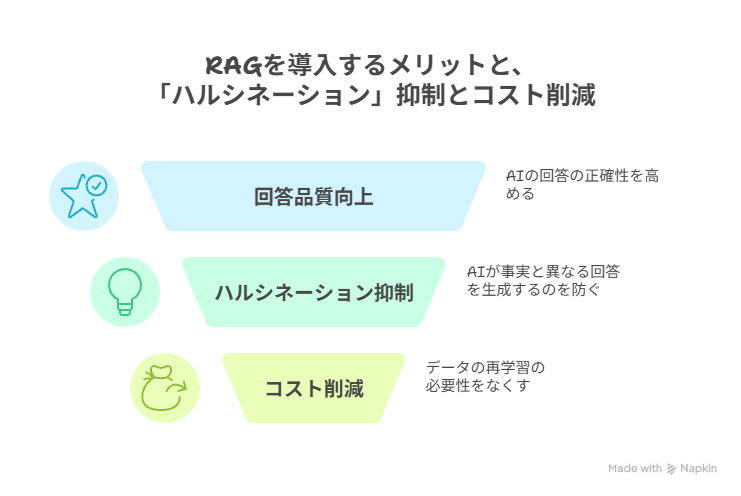
RAGを導入することで、生成AIの回答品質が大幅に向上し、ビジネスでの実用性が高まります。
特に、AIが事実と異なる回答を生成する「ハルシネーション」を抑制できる点と、データの再学習が不要なためコストを削減できる点が、大きなメリットとして注目されています。
最新情報や社内独自の専門知識に基づいた回答が可能
従来の生成AIは、学習時に取り込んだデータしか参照できないため、学習後に発生した最新情報や、企業の社内ドキュメントなどの非公開データには対応できませんでした。
しかし、RAGでは外部のデータベースからリアルタイムで情報を検索するため、最新の情報や社内の専門知識を常に参照できます。
例えば、最新の法規制や社内マニュアル、過去のプロジェクト資料など、学習データに含まれていない情報でも、データベースに保存されていれば即座に活用できます。
そのため、AIは常に最新で正確な情報に基づいた回答を提供できるようになります。
AIの課題「ハルシネーション」を劇的に減少させる
ハルシネーションとは、AIが事実と異なる内容を生成してしまう問題です。
従来の生成AIは、学習データに含まれていない情報について推測で回答するため、時には事実と異なる内容を生成してしまうリスクがありました。
しかし、RAGでは回答を生成する際に必ず外部データベースから検索した情報を参照するため、根拠のない推測による回答を大幅に減らせます。
ただし、検索した情報自体が間違っている場合は、その情報に基づいた回答になる可能性があるため、データベースの品質管理も重要です。
それでも、根拠のない推測による回答よりも、検索した情報に基づく回答の方がはるかに信頼性が高いといえるでしょう。
出典(ソース)の明示により回答の信頼性が向上
従来の生成AIは、どの情報源に基づいて回答を生成したのかを明示できず、回答の信頼性を確認することが困難でした。
しかしRAGを活用することで、検索した情報源を明確に示すことができるため、ユーザーは回答の根拠を確認できます。
例えば、「この回答は、2024年1月の会議録と社内マニュアル第3章に基づいています」といった形で、情報源を明示できます。
そのため、ユーザーは回答の信頼性を判断でき、必要に応じて元の文書を確認することもできます。
データの再学習(ファインチューニング)不要によるコスト削減
従来の方法では、新しい情報をAIに学習させるために、大規模なデータセットを準備し、専門的な技術と計算リソースを使って再学習(ファインチューニング)を行う必要がありました。
一方、RAGでは、新しい情報をデータベースに追加するだけで、即座にAIがその情報を参照できるようになります。
そのため、再学習に必要となる計算リソースや専門家の作業時間が不要となるので、運用コストを大幅に削減できます。
週30件の会議も数百頁の資料も、AIが一括解析。要約からスライド作成まで数分で完結。
RAGの活用例|ビジネス現場でどう使われている?
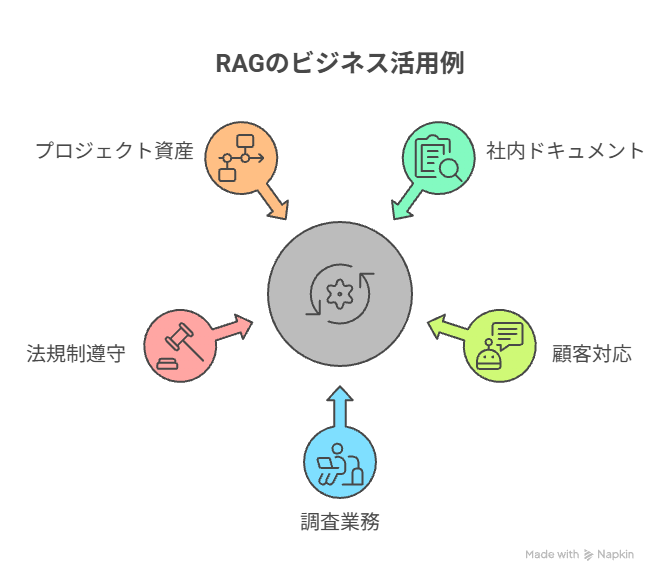
RAGは、さまざまなビジネスシーンで実用化が進んでいます。
社内のナレッジ共有から顧客対応、調査業務まで、幅広い分野で活用されています。
ここでは、実際のビジネス現場でRAGがどのように使われているか、具体的な活用例を紹介します。
社内ドキュメントやマニュアルのナレッジ共有
「新入社員の研修手順は?」「この業務の承認フローは?」といった質問に、社内のマニュアルや業務手順書から即座に回答を得られるという点が、RAGを活用したナレッジ共有の一例です。
多くの企業では、社内のドキュメントが大量に蓄積されているものの、必要な情報を素早く見つけることが難しいという課題があります。
RAGを導入すれば、従業員は自然な言葉で質問するだけで、関連する社内ドキュメントから必要な情報を即座に取得できます。
情報検索の時間を大幅に短縮し、社内の知識を効率的に共有できるようになります。
顧客対応チャットボットの高度化
従来のチャットボットは、あらかじめ設定された回答パターンに基づいて動作するため、複雑な質問や最新情報に関する質問には対応できませんでした。
しかし、RAGを導入することで、チャットボットは商品カタログ、FAQ、過去の問い合わせ履歴などから情報を検索し、より正確で詳細な回答を提供できるようになります。
「この商品の最新の仕様は?」という質問に対して、RAGは最新の商品カタログや仕様書から情報を検索し、正確な回答を生成します。
その結果、顧客満足度の向上と、問い合わせ対応の効率化を同時に実現できます。
専門的な調査・リサーチ業務の効率化
研究機関やコンサルティング企業では、膨大な量の論文、レポート、市場調査資料などを扱います。
必要な情報を素早く見つけることが困難だったこの分野で、RAGは大きな効果を発揮します。
研究者やアナリストは自然な言葉で質問するだけで、関連する資料から必要な情報を抽出できます。
「過去5年間の市場動向に関する分析は?」という質問に対して、RAGは関連するレポートや分析資料から情報を検索し、要点をまとめて回答します。
調査時間を大幅に短縮できるため、より深い分析に時間を割けるようになります。
最新の法規制やコンプライアンス遵守の自動チェック
法務やコンプライアンス部門では、常に最新の法規制やガイドラインを把握し、社内の業務がそれらに準拠しているかを確認する必要があります。
RAGを導入することで、最新の法規制データベースやコンプライアンスガイドラインから情報を検索し、社内の業務や文書が規制に準拠しているかを自動的にチェックできます。
「この契約書は最新の法規制に準拠していますか?」という質問に対して、RAGは最新の法規制データベースから関連情報を検索し、準拠状況を確認します。
この方法により、コンプライアンス違反のリスクを低減し、法務業務の効率化を実現できます。
膨大な過去プロジェクト資産からの類似事例検索
過去のプロジェクトの資料、提案書、報告書などが大量に蓄積されていても、類似のプロジェクト事例を素早く見つけることは容易ではありません。
RAGを導入すれば、プロジェクトマネージャーや営業担当者は、自然な言葉で質問するだけで、過去の類似プロジェクトから参考になる情報を即座に取得できます。
「同様の規模のプロジェクトで、どのような課題がありましたか?」という質問に対して、RAGは過去のプロジェクト資料から類似事例を検索し、課題や解決策をまとめて回答します。
この機能により、過去の経験を活かした効率的なプロジェクト運営が可能になります。
RAG導入の課題と失敗しないための注意点
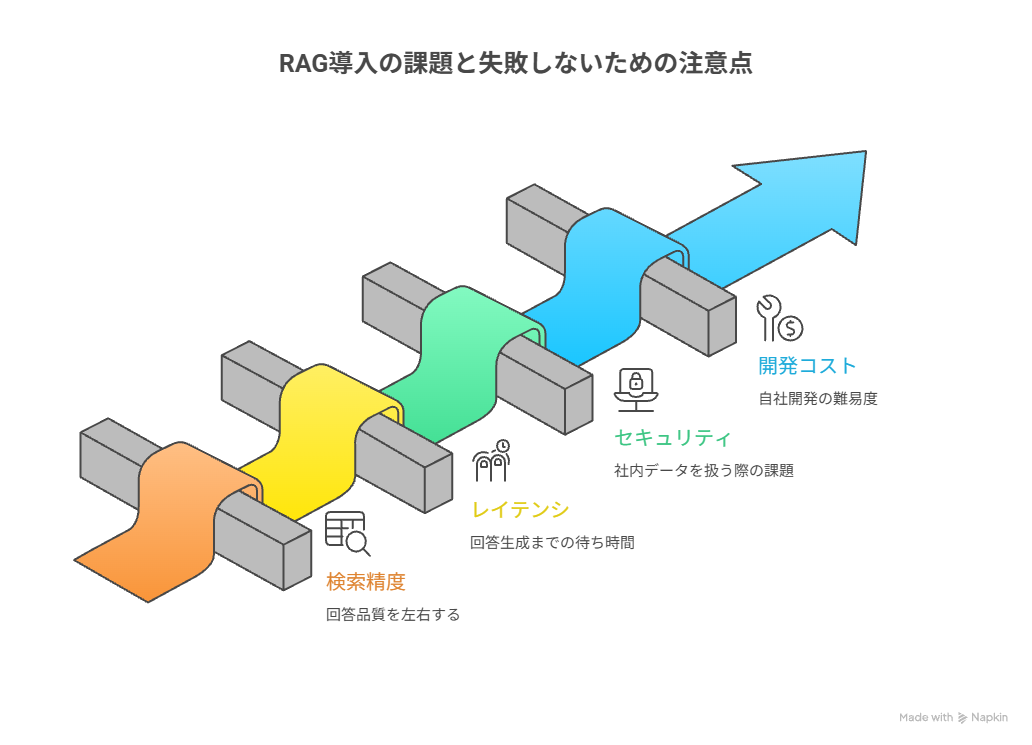
RAGは多くのメリットがありますが、導入時には注意すべき課題もあります。
検索精度、レイテンシ、セキュリティ、開発コストなど、事前に理解しておくことで、失敗を防ぎ、効果的な導入が可能になります。
ここでは、RAG導入時に直面する主な課題と、失敗しないための注意点を解説します。
検索精度が回答品質を左右する「GIGO」の問題(データ整備の重要性)
「GIGO(Garbage In, Garbage Out)」は、直訳すると「ゴミを入れればゴミが出る」という意味ですが、この言葉のように、RAGの回答品質は検索されるデータの質に大きく依存します。
データベースに保存されている情報が古かったり、不正確だったりすると、RAGはその情報を基に回答を生成するため、結果として不正確な回答が生成されてしまいます。
また、データが適切に構造化されていない場合、検索精度が低下し、関連性の低い情報が検索される可能性があります。
そのため、RAGを導入する際は、データの整備が極めて重要です。
定期的なデータ更新、データの構造化、重複データの排除など、データ品質の管理を徹底することで、RAGの回答品質を向上させることができます。
回答生成までのレイテンシ(待ち時間)と対策
RAGでは、質問を受けてから回答を生成するまでに、情報の検索と生成という複数のステップを経る必要があります。
そのため、従来の生成AIと比べて、回答までの待ち時間(レイテンシ)が長くなる傾向があります。
特に、大量のデータベースから情報を検索する場合や、複雑な質問の場合、レイテンシが数秒から数十秒に及ぶこともあります。
この問題を解決するためには、データベースの最適化、検索アルゴリズムの改善、キャッシュ機能の活用などが有効です。
また、ユーザーに対して回答生成中であることを明示し、待ち時間を意識させない工夫も重要です。
社内データを扱う際のセキュリティとアクセス権限管理
RAGを社内データに適用する場合、セキュリティとアクセス権限の管理が重要な課題となります。
特に、社内の機密情報や個人情報を扱う際は、適切なセキュリティ対策が必要です。
具体的にはデータベースへのアクセス制御、データの暗号化、通信の暗号化など、多層的なセキュリティ対策が挙げられます。
また、営業部門のデータは営業部門のメンバーのみがアクセスできるようにするなど、役割に応じたアクセス権限の管理も重要となります。
RAGシステムを導入する際は、セキュリティポリシーを明確にし、定期的なセキュリティ監査を実施することで、情報漏洩のリスクを低減できます。
自社開発の難易度|エンジニアリソースと構築コスト
RAGを自社で開発する場合、高い技術的専門性と相当なリソースが必要になります。
ベクトルデータベースの構築、検索アルゴリズムの実装、AIモデルとの連携など、複雑な技術要素を組み合わせる必要があります。
そのため、専門的な知識を持つエンジニアの確保や、開発に必要な時間とコストが課題となります。
この課題を解決するためには、既存のRAGサービスやプラットフォームを活用する方法が非常に有効です。
構築・開発不要で利用できるサービスを選択することで、エンジニアリソースと構築コストを大幅に削減できます。
【解決策】Notta Brain:会議データを資産に変えるRAG搭載AI
RAGの課題を解決し、すぐに活用できるソリューションとして、Notta Brainをご紹介します。
Notta Brainは、会議録を自動でAIナレッジベース化するRAG搭載のAIサービスです。
構築・開発不要で、会議データを即座に活用できるため、RAG導入のハードルを大幅に下げることができます。
構築・開発不要!会議録を即座に「AIナレッジベース」化
Notta Brainの最大の特徴は、構築・開発が一切不要であることです。
従来、RAGを導入するには、ベクトルデータベースの構築や検索アルゴリズムの実装など、専門的な技術と時間が必要でした。
しかし、Notta Brainでは、会議録をアップロードするだけで、自動的にAIナレッジベースが構築されます。
エンジニアを配置する必要も、開発コストをかける必要もありません。
会議録をアップロードすると、RAG技術により会議内容が自動的に整理され、検索しやすい状態になります。
そのため、技術的な知識がない方でも、すぐにRAGの恩恵を受けることができます。
RAG技術により、過去の文脈や発言者を踏まえた正確な回答を実現
Notta BrainのRAG技術を活用することで、過去の会議の文脈や発言者を踏まえた正確な回答を実現します。
例えば、「前回の会議で山田さんが提案した内容は?」という質問に対して、Notta Brainは過去の会議録から該当する発言を検索し、山田さんが提案した内容を正確に回答します。
また、「このプロジェクトの経緯を教えて」という質問に対しては、複数の会議録から関連する情報を統合し、時系列に沿って説明します。
RAG技術により、会議録全体から関連情報を検索し、文脈を理解した上で回答を生成するため、単なるキーワード検索では見つけられない、意味的に関連する情報も正確に抽出可能です。
構造化されていない会話データも自動で整理・活用可能に
通常の議事録は発言の順序、話題の切り替え、議論の展開などが自然な会話形式で記録されているため、従来の検索方法では必要な情報を見つけることが困難でした。
しかしNotta Brainは、このような構造化されていない会話データを自動で整理し、活用可能な状態にします。
会議録をアップロードすると、RAG技術により会話内容が意味的に理解され、自動的に整理されて検索しやすい状態になります。
そのため、「この議題について誰が何と言ったか」といった自然な質問に対して、正確な回答を得ることができます。
現場の業務効率を劇的に高める具体的な活用シーン
Notta Brainは、さまざまな業務シーンで活用できます。
例えば、新入社員が過去の会議録から業務の経緯や決定事項を確認する際、自然な言葉で質問するだけで、関連する会議録から必要な情報を即座に取得できます。
また、プロジェクトの引き継ぎ時には、「このプロジェクトの課題は何だったか?」という質問に対して、過去の会議録から課題や議論の内容を抽出できます。
さらに、顧客との打ち合わせの準備として、「この顧客との過去の会議で決まったことは?」という質問で、過去の会議内容を素早く確認できます。
このように、Notta Brainを活用することで議事録を単なる記録ではなく、業務効率を高める資産として活用できるようになるのです。
RAG(検索拡張生成)に関するよくある質問(FAQ)
RAGとファインチューニング(追加学習)はどのように使い分けるべき?
RAGは、外部データベースから情報を検索して回答を生成する方法で、データの更新が容易でコストが低いのが特徴です。
一方、ファインチューニングは、AIモデル自体を再学習させる方法で、特定のタスクに特化できますが、コストと時間がかかります。
最新情報や頻繁に更新されるデータを扱う場合はRAG、特定の業務フローをAIに学習させたい場合はファインチューニングが適しています。
RAGを導入すれば、AIの嘘(ハルシネーション)は100%防げますか?
残念ながら、RAGを導入してもハルシネーションを100%防ぐことはできません。
ただし、RAGはハルシネーションを大幅に減少させることができます。
外部データベースから検索した情報を基に回答を生成するため、根拠のない推測による回答を減らせます。
ただし、検索した情報自体が間違っている場合は、不正確な回答が生成される可能性があるため、データベースの品質管理が重要です。
PDFやExcelなど、非構造化データもRAGで読み込めますか?
はい、PDFやExcelなどの非構造化データもRAGで読み込むことができます。
RAGシステムは、これらのファイル形式からテキストを抽出し、データベースに保存して検索可能な状態にします。
ただし、画像のみのPDFや、複雑な表形式のExcelなど、テキスト抽出が困難な場合は、事前にデータを整理しなければならない場合があります。
多くのRAGサービスでは、PDF、Excel、Word、PowerPointなど、様々なファイル形式に対応しています。
社内機密データをRAGに使用しても情報漏洩の心配はありませんか?
セキュリティ対策を適切に講じれば、社内機密データをRAGに使用しても安全です。
クラウド型のRAGサービスを利用する場合は、サービス提供者のセキュリティ対策を確認する必要があります。
一方、オンプレミス型(自社サーバー内)でRAGを構築する場合は、データを社内で管理できるため、より高いセキュリティを確保できます。
また、アクセス権限の管理により、必要な人だけがデータにアクセスできるようにすることも重要です。
まとめ|RAG(検索拡張生成)を理解してビジネスを加速させよう
RAG(検索拡張生成)は、生成AIの回答精度を大幅に向上させる革新的な技術です。
外部データベースから情報を検索し、その情報を基に回答を生成する仕組みにより、最新情報や社内の専門知識に基づいた正確な回答が可能になります。
また、ハルシネーションを大幅に減少させ、回答の出典を明示できるため、ビジネスでの実用性が高まっています。
RAGを導入することで、社内のナレッジ共有、顧客対応、調査業務など、さまざまな業務の効率化が期待できます。
構築・開発不要で利用できるサービスも登場しており、今こそRAGを活用してビジネスを加速させるタイミングです。
本記事が、RAGの理解と導入の参考になれば幸いです。
複数ファイルを一括分析する

