

AI音声認識で業務効率化|導入事例・選定ポイントをわかりやすく解説
業界トップの正確率で作業効率爆上げ!
AI音声認識の市場規模は2021年の83億米ドルから2026年に220億米ドル到達と予測されており、成長スピードが早いです。音声認識の市場規模が成長しつづける理由としては、ユーザーの音声認識技術を利用した製品需要の高まりがあるためです。そのため、音声認識技術へ投資する企業が増えており、注目されています。
しかし、音声認識技術は製品やサービスによって、さまざまな特徴や選定ポイントがあり、迷いが生じて迅速に導入できない場合も少なくありません。そこで今回は、AI音声認識の仕組みや活用事例、選定法などを解説します。AI音声認識技術の導入を検討されている方は、ぜひ参考にしてください。
AI音声認識とは
AI音声認識(Automatic Speech Recognition, ASR)とは、人間が話した言葉をコンピューターが音声データとして解析し、テキストデータへ変換する技術です。キーボード入力よりも速く、誤入力も減らせる手段として注目されており、ディープラーニング(深層学習)などAI技術の導入によって認識精度が飛躍的に向上しました。
近年ではスマートフォンの音声入力(SiriやGoogleアシスタント)、スマートスピーカーなどにも搭載され、日常生活やビジネスのさまざまな場面で広く活用されています。たとえばコールセンターでの通話内容のテキスト化や、製造現場での音声入力による作業記録など、中小企業においても業務効率化やサービス向上を目的に導入が進んでいる技術です。
音声認識技術は一般に「ASR(Automatic Speech Recognition)」とも呼ばれます。一方で「ボイスレコグニション(Voice Recognition)」という用語は話者を特定する技術(話者認識)を指し、「誰が話したか」を識別するものであり、本記事で扱う音声認識(「何を話したか」を文字化する技術)とは異なる概念です。混同しやすい用語ですが、それぞれ目的が違うため注意しましょう。
AI音声認識の技術的仕組み
AI音声認識システムが音声をテキストに変換するまでには、大きく分けて4つの工程を経ています。以下はその一般的な流れと仕組みです。
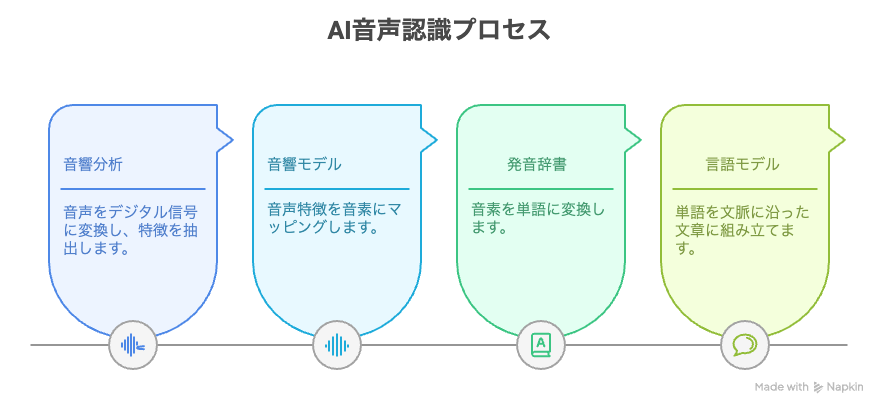
音響分析(特徴抽出)
まずマイクなどから入力された音声をデジタル信号に変換し、コンピューターが処理しやすい形に整形します。録音した音声波形から周波数成分や音の強弱などの特徴量を抽出し、ノイズの除去もおこないます。音響分析によって人間の耳で聞く音声からAIが扱える数値データへと変換が可能です。
音響モデル(音素認識)
音響分析に続いて抽出された特徴量をもとに、音声がどの音素に対応するかを判別します。音素とは言語を構成する最小の音単位で、日本語では母音・子音・撥音などがあります。古典的には隠れマルコフモデル(HMM)などの統計手法で時間的な音の変化をモデル化してきました。
現在の主流であるDNN-HMM型のシステムでは、ディープニューラルネットワーク(DNN)による特徴量の分類とHMMによる時系列確率モデルを組み合わせ、高精度な音素認識を実現しています。
発音辞書(単語化)
音素列を単語に対応付ける工程です。発音辞書には音素列と単語の対応関係(読み仮名と単語のデータベース)が登録されています。音響モデルが出力した音素列を発音辞書で照合し、どの単語になり得るかを割り出します。
たとえば「か・き・く」という音素列から「柿」「夏季」など候補を引き当てるイメージです。単語化の段階で音声はまだ単語の羅列に過ぎないため、次の工程で文脈に沿ったテキストへと組み立てます。
言語モデル(文章化)
単語列を文脈に沿った自然な文章へ組み立てる工程です。言語モデルは大量のテキストデータから学習した単語の出現確率や文法構造のモデルで、直前の単語から次に来る単語を予測したり不自然な語の組み合わせを調整したりします。
たとえば「雨が降る」と「雨が振る」のような同音異義語も、言語モデルによって文脈に適した漢字に変換されます。また言語モデルにはN-gramや近年ではニューラルネットワークを用いたものがあり、より長い文脈や複雑な構文も考慮して文章を構成します。最終的に人間が読みやすいテキストデータが出力されます。
技術発展
音声認識技術の研究開発は数十年にわたる歴史があります。技術発展の黎明期から現在までの技術発展の流れを解説します。
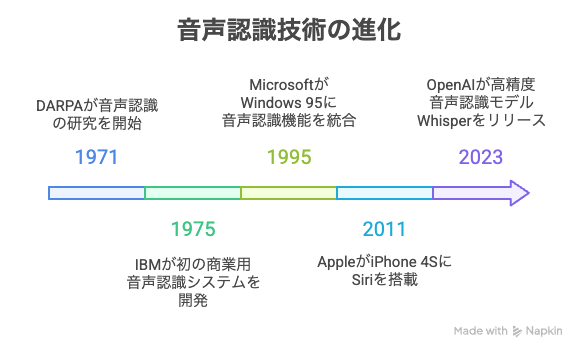
初期の研究(〜1970年代)
音声認識の本格的な研究は1971年に米国DARPA(国防高等研究計画局)によって開始されたとされています。当時は軍事目的の研究の一環で、限られた語彙の認識からスタートしました。また1970年代半ばには、アメリカで民間初の音声認識技術としてIBMが1975年に音声認識システムを開発し注目を集めました。この頃の技術はまだ単語ごとに区切って話さなければならないなど限定的でしたが、音声認識の可能性が見出された時代です。
HMM時代(1980〜90年代)
1980年代から1990年代にかけて、音声認識には隠れマルコフモデル(HMM)に代表される統計的手法が主流となりました。大量の音声データから音素の出現確率を学習し、未知の音声を確率的に最も近い単語列へとデコードする仕組みです。
この時期にはパソコン上で動作する音声認識ソフトも登場し、1995年にはMicrosoftがWindows 95に簡単な音声認識機能を搭載するなど一般ユーザーへの普及のきっかけも生まれました。しかし、認識精度や処理速度には限界があり、長らく音声認識は実用面でニッチな存在でした。
ディープラーニングの導入(2000〜2010年代)
2000年代後半から2010年代にかけて、計算機ハードウェアの進化とビッグデータの蓄積により、AI(人工知能)技術、ディープラーニングの手法が音声認識に導入されました。2011年にはAppleのiPhone 4Sに搭載された音声アシスタントSiriが登場し、音声認識が一般に広く認知される期間となりました。
2010年代前半には、Hinton氏らの研究でディープニューラルネットワークを音響モデルに適用することで認識精度の向上が報告されています。以降主要な音声認識エンジンは次々とディープラーニング対応へ移行しました。
その結果、英語音声認識の評価指標である単語エラー率(WER)は、2010年代後半までに人間の聞き取り精度に迫るレベルまで低下しました。
End-to-Endモデルと現在(2020年代)
2016年頃からは、音声波形から直接テキストをエンドツーエンドで生成するEnd-to-End型音声認識の研究が進展し始めました。エンドツーエンドモデルには畳み込みニューラルネットやリカレントネット、最近ではTransformerアーキテクチャを用いたものも登場し、高精度化と学習効率の向上が図られています。
2020年代には、GoogleやMicrosoftといった大手のクラウドAPIでもエンドツーエンド技術が採用され始め、長時間音声や雑音環境での性能改善が進んでいます。また、2023年にはOpenAIがオープンソースの高精度音声認識モデルWhisperを公開し話題となりました。
そのため、開発者コミュニティでも手軽に高度な音声認識を利用できるようになりつつあります。現在では研究分野ではEnd-to-End型が主流となり、商用でもディープラーニングによる音声認識が当たり前の時代となっています。
業界別実践活用事例

製造業での品質管理・作業効率化
製造現場では、検査結果や作業記録の音声入力によって業務効率を高めた事例があります。たとえば、ある素材メーカーでは従来、検査数値を紙にメモして後でPCに転記していましたが、音声認識ソフトを導入し検査場で作業者が結果を音声で入力する運用に切り替えました。
その結果、検査業務にかかる時間が約33%削減され、手書き用紙も大幅に削減されました。音声入力が騒音環境下でも安定して動作するため、転記ミスがなくなり品質管理の精度向上にも役立っています。
コールセンター・顧客対応の高度化
コールセンター業務では、AI音声認識がオペレーター支援や応対品質の分析に活用されています。通話内容をリアルタイムで文字起こしし、オペレーターの画面に表示することで顧客対応のスピードアップと入力ミスの防止につなげている企業があります。
文字起こしされた通話ログは、そのまま応対記録として残すほか、キーワード分析による課題抽出にも利用可能です。実際に、ある証券会社では全店の通話をAIでモニタリングし、顧客対応の共通課題を発見してサービス改善に活かす取り組みが行われています。
また、FAQにない問い合わせを音声認識データから検出してナレッジ化するなど、顧客対応のDXにも繋がっています。
医療・ヘルスケアでの記録作成効率化
医療現場でも音声認識がカルテ作成や報告書作成の効率化に貢献しています。医師が診察しながら口述した内容をリアルタイムで文字起こしすると、キーボード入力の手間を省きつつ記録を残せます。
たとえば、病院で電子カルテへの入力補助として音声認識を導入したケースでは、パソコン操作に不慣れな高齢医師でもスムーズにカルテ記載が行えるようになりました。音声入力により複雑な医療専門用語も辞書登録での対応が可能で、後から必要に応じて修正は必要ですが全体の事務負担が軽減されています。
会議の議事録作成・社内文書化
社内会議や打ち合わせの自動議事録作成も多くの企業で試されています。会議中にAIが発言を文字起こしし、参加者は会話に集中するだけで会議終了後には議事録がほぼ完成しているという運用も可能です。発言者ごとの話者識別や要約機能を備えたツールもあり、後でテキストを清書・要約する手間を省けます。
実際に自治体の会議で音声認識システムを導入し、聴覚障害のある職員でもリアルタイムに議論内容を文字で追える環境を整備した例もあります。この自治体ではAIによる会議音声の自動要約や、多言語翻訳機能も試験的に活用しており、情報共有のアクセシビリティ向上につなげています。
メディア・字幕制作とコンテンツ制作
テレビ放送やオンライン動画の字幕制作にも音声認識が活用されています。特にライブ配信や生放送の場面では、人手でリアルタイム字幕を付与するのは困難ですが、AIによりほぼリアルタイムの自動字幕表示が可能となりました。まだ完璧な精度ではないものの、実況中継などで実用化される可能性が高いです。
また、録画済み動画の字幕起こしやテロップ制作でも時短効果を上げています。メディア以外にも、インタビューの文字起こしや議事録共有を迅速化することで情報発信のスピードを上げている企業もあります。
その他の業界での活用
上記以外にも、多言語対応が求められる場面での音声認識活用も顕著です。たとえば観光業界では、ホテル受付に多言語音声認識と自動翻訳機能を備えたサービスを導入し、外国人客とスタッフのコミュニケーション円滑化に成功した事例があります。
実際に東急ホテルズでは22言語対応の音声翻訳システムを試験導入し、スタッフと海外ゲスト間の意思疎通をスムーズにしたと報告されています。語学の壁をAIが埋める形でサービス品質を向上させているケースです。
また、教育分野では講義内容をリアルタイム文字起こしして学生が後で検索・復習できるようにしたり、公共サービスでは電話の自動音声受付(音声ボット)で人手対応を補完したりする取り組みも行われています。
製品選択の選定法

| チェック項目 | 内容 | 評価基準 | 優先度(高・中・低) |
|---|---|---|---|
| 認識精度 | 自社の音声(会議・現場録音等)での正確性 | テスト利用時の認識率(%)・誤変換頻度 | 高 |
| 対応言語・専門用語 | 日本語精度や必要な言語、業界特有用語への対応 | 日本語辞書の充実度、専門用語登録機能 | 高 |
| 操作性 | 現場スタッフが直感的に使えるか | UIの分かりやすさ、操作手順の少なさ | 中 |
| 付加機能 | 話者識別、要約、翻訳、句読点自動挿入、API連携など | 必要機能の有無と精度 | 中 |
| 導入形態 | クラウド型/オンプレ型 | 自社セキュリティポリシーとの適合 | 高 |
| コスト | 初期費用・月額費用・従量課金などの総額 | 予算内か、費用対効果 | 高 |
| セキュリティ | データ暗号化、保存方法、外部送信の有無 | 社内規定・法令順守の可否 | 高 |
| サポート体制 | 導入時・運用時のサポートの充実度 | 日本語対応、サポート時間、対応チャネル | 中 |
| 導入実績 | 同業種での利用事例の有無 | 事例数・効果報告 | 中 |
| 将来性 | 機能更新やAI精度向上の見込み | 定期アップデート頻度、ロードマップ公開 | 低 |
音声認識の精度
まず最重視すべきは認識精度です。製品ごとに得意な音声や言語が異なり、精度にも差があります。精度が低いと結局手修正の手間が増え効果が薄れるため、可能であればトライアル版で自社の音声を試し、認識率を確認しましょう。口コミや第三者評価も参考になります。
対応言語・専門用語
自社の業務で使われる言語や専門用語への対応も重要です。登録されているボキャブラリー(単語数)が豊富なほど自然で正確な文章になりやすいです。特定業界向けに専門用語をあらかじめ多く収録した製品や、ユーザーが単語をカスタム登録できる機能がそろったものを選びましょう。
操作性・使いやすさ
ソフトやサービスの操作が複雑だと、現場で使いこなせず定着しません。UIが直感的であること、録音開始や文字起こし結果の編集が簡単にできることなどを確認しましょう。可能であればトライアル利用やデモで実際の操作感をチェックし、現場スタッフでも扱えるか評価することをおすすめします。
機能面(付加機能や連携)
単に文字起こしだけでなく、どんな付加機能が必要かを整理しましょう。たとえば話者分離(誰が話したか識別)、句読点の自動挿入、翻訳機能、リアルタイム要約、他の業務システムとの連携(API提供)など製品によって特色があります。自社の利用目的に必須な機能(例:会議録なら話者識別と要約機能)が備わっているかを事前に確認し、不要な機能にコストを払いすぎないようにします。
コストと導入形態
予算内で導入できるかも現実的なポイントです。製品には初期費用や月額料金、従量課金などさまざまな料金体系があります。価格だけでなく、含まれるサービス内容(サポート体制やアップデート費用)も考慮しましょう。
クラウドサービス型であればサーバ管理コストが不要な代わりに利用料がかかり、オンプレミス型は自社サーバ設置でランニングコストは読みにくいがデータセキュリティは高いという違いもあります。自社のセキュリティポリシーや運用体制に合わせて最適な形態を選ぶことも重要です。
主要製品比較

現在利用できる主なAI音声認識サービスや製品には、グローバルに提供されているクラウドAPIから国内企業による専門特化型までさまざまなものがあります。ここでは代表的な主要製品・サービスの特徴を比較します。
| 製品・サービス名 | 特徴・強み | 想定用途・適した場面 |
|---|---|---|
| Google Cloud Speech-to-Text | ・125以上の言語に対応 ・高度なAIで高精度 ・オフラインモデルも提供 ・句読点自動挿入 ・コンテンツフィルタリング機能 | 多言語にまたがるサービスの音声入力やグローバル展開する製品。 |
| Amazon Transcribe | ・AWSのクラウド型音声認識 ・用途別APIを提供(通話解析用のCall Analyticsや医療特化のTranscribe Medical) ・話者識別の精度高 ・番号読み上げの正規化 | コールセンターの通話記録分析、医療現場の音声記録など。 |
| Microsoft Azure Speech Service | ・音声からの文字起こし ・音声合成(読み上げ) ・リアルタイム翻訳 ・話者認識 ・セキュリティ対策(3,500人超のセキュリティ専門家による保護体制) | 多言語会議のリアルタイム翻訳、音声ボット、セキュリティ重視の企業システム。 |
| IBM Watson Speech to Text | ・IBMのWatson AIを活用した高性能な音声認識 ・業種ごとの専門用語モデル提供あり ・クラウドでもオンプレミスでも導入可能 | コールセンター向けシステム、機密性の高い社内システム(オンプレ導入)。 |
| AmiVoice(Advanced Media社) | ・日本発・国内シェアNo.1の音声認識エンジン ・議事録作成、コンタクトセンター、医療、製造など用途別に最適化されたエンジン群を提供 ・幅広い業界の専門用語に対応可能 | 日本語の精度を重視する用途全般(医療音声入力、工場での検品記録、会議議事録など幅広いシーン)。 |
| NTT SpeechRec(NTTテクノクロス) | ・最新AI「MediaGnosis」を搭載 ・用途・業界に合わせチューニングが可能 ・雑音環境下でも高精度の認識性能 ・顔画像やテキスト情報も統合処理可能など独自機能あり | コールセンター(雑音の多い通話のテキスト化)、議事録作成、映像+音声の解析(マルチモーダル活用)など。 |
導入成功のための対策

AI音声認識で押さえておくべき導入成功のポイントをいくつか解説します。
導入目的とKPIの明確化
まず「なぜ音声認識を導入するのか」をはっきりさせましょう。たとえば「問い合わせ対応の時間を○%短縮する」「議事録作成工数を半減する」など、具体的な目標KPIを設定します。目的が曖昧なままだと社内説得や投資対効果の評価が困難です。仮説検証を重ね、期待効果を定量化した上で経営層の了承を得ることが成功への第一歩です。
小規模テスト導入(PoC)の実施
いきなり全社展開するよりも、まずは小規模な実証実験(PoC)をおこなうことをおすすめします。たとえば一部署や限られた期間で音声認識を試用し、その結果を測定します。精度や使い勝手、業務フローへのインパクトを確認し、問題点があれば改善策を検討しましょう。PoCの結果は社内展開への説得材料にもなり、導入後のトラブル低減にもつながります。
現場環境の整備(音質向上など)
音声認識の精度を最大化するためには、録音環境にも配慮が必要です。高品質なマイクの用意や雑音の多い現場ではノイズキャンセリングマイクの利用、通話録音なら録音レベルの適切な設定など、ハード面の準備をおこないます。コンピューターは人間ほどノイズ耐性が高くないため、可能な限りクリアな音声を入力することが正確な認識に直結します。
カスタム辞書や学習機能の活用
適用業務によっては、専門用語や社内独自の言い回しが認識されにくい場合があります。その際はツールのカスタム辞書登録機能を活用し、よく使う専門用語や略語を事前に登録しましょう。たとえば「〇〇株式会社」を「まるまるかぶしきがいしゃ」と読む、といった固有名詞を登録できます。また、同音異義語対策として文章例を学習させる仕組みがあれば併用しましょう。認識精度が向上し現場の手直し負担を減らせます。
ユーザートレーニングと周知
新しいツールを導入する際には、実際に使う従業員への教育も不可欠です。音声認識の使い方(たとえば録音開始/停止の操作、結果テキストの編集方法)をトレーニングし、現場で戸惑いなく使えるようにします。
また、「完全な自動化ではなくある程度の誤認識は起こり得る」ことも周知し、誤りを訂正する手順や責任分担も決めておきます。過度な期待を抱かせず現実的な運用フローを設計することが大切です。現場からのフィードバックを集め改善に活かす姿勢も示しましょう。
継続的な改善とアップデート
導入して終わりではなく、定期的なシステム更新とチューニングをおこなうことが成功の鍵です。音声認識エンジンは技術進歩が早いため、新しいアルゴリズムやモデルが登場した際には積極的に取り入れて性能向上を図ります。
クラウドサービスの場合は自動更新されることも多いですが、オンプレミスの場合はアップデート計画を立てましょう。また、ユーザーから寄せられた誤認識事例を分析し、辞書登録や話し方の工夫など具体的な対策を講じます。継続的改善のサイクルを回すと、時間経過とともに精度と使い勝手が向上し、導入効果を最大限に引き出せます。
セキュリティとプライバシーへの配慮
音声データには機密情報が含まれる可能性があります。クラウド音声認識を使う場合は、録音データが外部サーバーに送信されるため情報セキュリティ対策を確認してください。
必要に応じて通信の暗号化や保存データの匿名化、クラウド利用規約の精査をおこないましょう。顧客との通話録音を文字起こしする場合は、プライバシーポリシー上の告知や許諾も考慮が必要です。社内ルールと照らし合わせ、安全に運用できる体制を築きましょう。
AI文字起こしツール「Notta」のご紹介
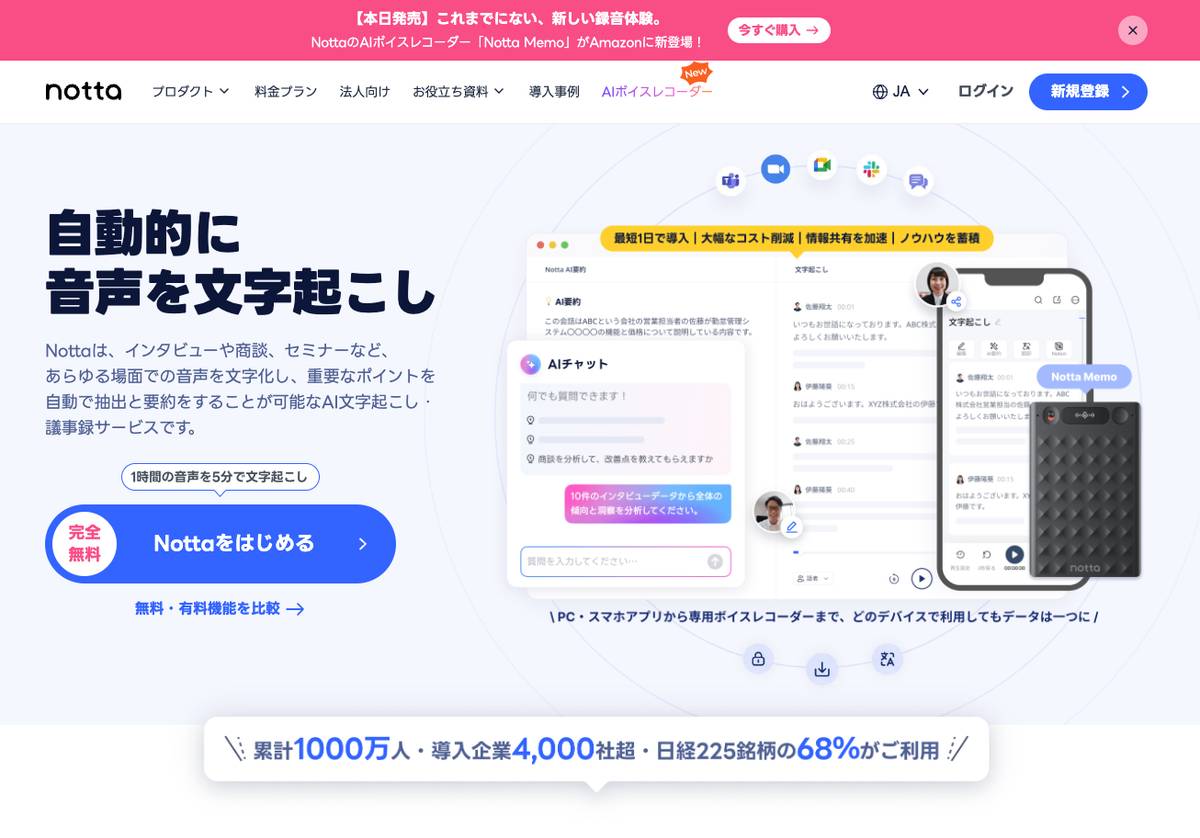
中小企業でも手軽に利用できるAI文字起こしクラウドサービスとして「Notta(ノッタ)」をご紹介します。Nottaは日本のスタートアップ企業・Notta株式会社が提供するクラウド型のAI議事録作成ツールで、ZoomやGoogle MeetなどのWeb会議をリアルタイムで文字起こしし録音データ化できるのが特徴です。
58言語以上に対応した音声認識エンジンを搭載し、多言語の自動翻訳や要約機能も備えているため、グローバルな会議や海外取引でも役立ちます。スマホアプリやChrome拡張などマルチデバイスに対応し、録音ファイルのアップロードから文字起こしも可能です。
たとえば会議後に音声ファイルをアップロードすればものの数分でテキスト化でき、議事録作成にかかる時間を大幅に短縮できます。生成されたテキストは要点抽出や編集も簡単に行え、チームで共有すると業務効率化につながるでしょう。無料プランでも毎月一定時間利用できるので、まずは試して自社ニーズに合うか確認してみてください。
Nottaが選ばれる理由は?
① 日本語特化のAIで業界トップの文字起こし正確率が実現、複数言語の文字起こしと翻訳も完璧対応
② 驚いほどの認識速度で文字起こし作業効率化が実現、一時間の音声データがただの5分でテキスト化
③ 国内唯一のGM・Zoom・Teams・Webex連携できるAI会議アシスタント、事前の日程予約から会議を成功に導く
④ AI要約に内蔵されるAIテンプレートで会議の行動項目、意思決定やQ&Aなどを自動作成
(カスタム要約テンプレートでインタビューや営業相談など様々のシーンでの効率化を実現)
⑤ 一つのアカウントでWeb、APP、Chrome拡張機能が利用でき、データの同期と共有はカンタン





